Research
My research is driven by public health challenges that emerge from analyzing complex and noisy datasets. For more details, including related papers and presentations, click on each project below. Alternatively, you can explore my papers by year here and my presentations by year here.
This work develops advanced statistical modeling techniques to build efficient and scalable computational frameworks for investigating decision-making in behavioral tasks, integrating data across multiple tasks, uncovering latent dynamics, and elucidating brain–behavior relationships. We aim to identify and quantify distinctive decision-making patterns associated with mental health conditions and diverse cognitive strategies, localize brain regions activated by specific tasks, and determine the causal effects of brain activity on behavior.
This work introduces statistical methodologies for integrating data from multiple randomized controlled trials, which may share a common treatment arm but differ in their alternative treatment options, to learn more robust and reliable individualized treatment rules. In addition, this work develops methods to integrate electronic health records from multiple hospitals while respecting data privacy and institutional sharing constraints, enabling more comprehensive and generalizable analyses across heterogeneous healthcare systems.
This work extends boosting methods by developing multiple strategies to handle missing and interval-censored response variables. These strategies are implemented using functional gradient descent, and we establish rigorous theoretical guarantees. Numerical studies demonstrate that the proposed methods perform well in finite-sample settings.
This work investigates joint models for genetic association involving longitudinal biomarkers and time-to-event outcomes. We develop and validate a closed-form sample size formula for assessing the overall effects of single-nucleotide polymorphisms. To improve robustness against model misspecification due to nonlinear trajectories in the longitudinal traits, we incorporate spline functions to capture subject-specific nonlinear evolutions.

This work addresses key challenges in missing data analysis by proposing a unified modeling framework based on generalized additive models. The framework flexibly accommodates a wide range of missing data mechanisms without relying on strong parametric assumptions. To enable simultaneous estimation and variable selection, it incorporates a regularized likelihood approach. The proposed method is supported by rigorous theoretical guarantees and demonstrates strong empirical performance across a variety of settings.

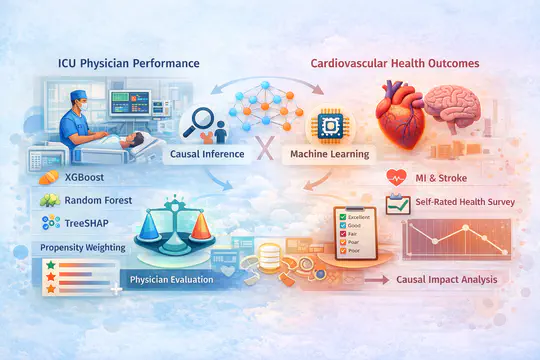
This work integrates causal inference, machine learning models, explainable AI tools, and statistical techniques to address challenges in public health and healthcare systems. The projects provide practical insights into the impact of cardiovascular infarctions on self-rated health and develop data-driven approaches for evaluating ICU physician performance, assessing drug effects on nausea and vomiting during pregnancy, and supporting hospital administrators in improving physician evaluation and enhancing the quality of patient care.
This work explores different models to analyze incubation times of COVID19 from different angles, finding that the current recommended 14 day quarantine time is not long enough to control the probability of an early release of infected individuals to be small.
This work applies machine learning and statistical modeling to real-world prediction problems involving social media influence, infrastructure reliability, and historical survival outcomes. The studies identify key predictive factors and compare model performance. The results highlight how data-driven approaches can uncover important drivers of outcomes, such as language accessibility in TED talk popularity, meteorological conditions in pipeline failures, and demographic characteristics in survival during the Titanic disaster.